该系列为本人的学习笔记,主要由本人整理书写而成。部分内容来自教材、视频课程等,不能保证完全原创性。
萌新的学习笔记,写错了恳请斧正。
# 排序的稳定性
先介绍一个概念,就是排序的稳定性。
排序算法的稳定性是指,如果待排序的序列中存在值相等的元素,经过排序后这些元素之间的先后顺序不变。简而言之,稳定的排序算法可以保留相等元素原本的相对顺序。
假设有一组人的年龄列表,有些人年龄相同:5,3,8,3,2。
如果我们对这个列表进行稳定排序,那么两个年龄为 3 的人在排序后的列表中,先出现的那个人在原列表中也是先出现的。
如果排序算法是稳定的,排序后我们得到的可能是这样:2,3 (第一个),3 (第二个),5,8。
如果排序算法是不稳定的,排序后可能得到:2,3 (第二个),3 (第一个),5,8,这里 3 的顺序被颠倒了,说明排序算法是不稳定的。
稳定性在某些场合下是很重要的。比如,在处理多关键字排序时,稳定性可以保证前一次排序的结果在后一次排序时不会被打乱。如果一个排序算法是稳定的,那么它可以更容易地被用于复杂的排序任务中。
# 一、插入排序
# 1.1 直接插入排序 (Insertion Sort)
直接插入排序是一种简单直观的排序算法。通过构建有序序列,对于未排序数据,在已排序序列中从后向前扫描,找到相应位置并插入。插入排序在实现上,通常采用原地排序,因此适合用于小规模数据。
直接插入排序的步骤:
- 从第一个元素开始,该元素可以认为已经被排序。
- 取出下一个元素,在已经排序的元素序列中从后向前扫描。
- 如果该元素(已排序)大于新元素,将该元素移到下一位置。
- 重复步骤 3,直到找到已排序的元素小于或者等于新元素的位置。
- 将新元素插入到该位置后。
- 重复步骤 2~5。
# 时间复杂度
在最坏的情况下,插入排序的时间复杂度为,其中 是数组的长度。在最好的情况下,如果数组已经是排好序的,插入排序的时间复杂度可以降低到,平均来说,其复杂度更接近。适用于小规模数据的排序或者原本就接近有序的情况。
# 实现
void InsertSort(int* arr, int n) | |
{ | |
for (int i = 0; i < n - 1; ++i) | |
{ | |
int end = i; | |
int tmp = arr[end + 1]; | |
while (end >= 0) | |
{ | |
if (tmp < arr[end]) | |
{ | |
arr[end + 1] = arr[end]; | |
--end; | |
} | |
else | |
{ | |
break; | |
} | |
} | |
arr[end + 1] = tmp; | |
} | |
} |
# 稳定性
直接插入排序是稳定的。
# 1.2 希尔排序 (Shell Sort)
希尔排序是插入排序的一种改进版本,也被称为 “缩小增量排序”。其核心思想是将原来要排序的列表分割成多个子序列,先让这些子序列基本有序,再对整个列表进行一次直接插入排序。这样做的目的是让数据移动的次数减少,从而达到减少排序时间的目的。希尔排序的效率比直接插入排序有显著提升。
希尔排序的步骤:
- 选择一个增量,我们先称之为 gap。(比方说对序列 {a1,a2,a3,...,an},我们可以取)
- 根据选择的增量序列,将待排序列分成多个子序列,每个子序列包含的元素不连续,但相距等于增量的元素归为同一子序列。(那么原序列就会被分为 n/2 个子序列,包括 {a1,a1+n/2},{a2,a2+n/2} 等)
- 对每个子序列分别进行直接插入排序。(让分出来的每一个子序列变的有序)
- 减小增量再次分组,重复第 3 步,直至增量减至 1,整个序列成为一个子序列,进行最后一次直接插入排序。(比方说第二次增量 gap 取,第三次取,最后一次则是 gap=1)
gap 的序列不一定要像我这样取(每次是上一次的一半),但是不同的增量序列会对这个算法的时间复杂度产生很大的影响。
# 时间复杂度
希尔排序的时间复杂度计算起来非常困难,或者说数学界都还没有给出一个合适的答案。
有人指出当 时,希尔排序的时间复杂度为,其中 是排序次数,。
还有人得出希尔排序在某个范围内比较次数约为 n1.3,当 n 趋于正无穷时,可以减少到。
如果我们使用 Knuth 提出的序列,即,那么时间复杂度约为。
但是我们还是可以知道希尔排序最坏情况下时间复杂度为,最好情况时间复杂度高于,一般情况下都远优于时间复杂度为的算法。
# 实现
void ShellSort(int* arr, int n) | |
{ | |
int gap = n; | |
while (gap > 1) | |
{ | |
gap /= 2; | |
for (int i = 0; i < n - gap; ++i) | |
{ | |
int end = i; | |
int tmp = arr[end + gap]; | |
while (end >= 0) | |
{ | |
if (tmp < arr[end]) | |
{ | |
arr[end + gap] = arr[end]; | |
end -= gap; | |
} | |
else | |
{ | |
break; | |
} | |
} | |
arr[end + gap] = tmp; | |
} | |
} | |
} |
# 稳定性
希尔排序是不稳定的。
# 二、选择排序
# 2.1 直接选择排序
直接选择排序是一种简单直观的排序算法。简单说就是在一堆数中,一次次从头到尾挑出最小的数,然后依次排列起来。
直接选择排序的步骤:
- 在未排序序列中找到最小(最大)元素,存放到排序序列的起始位置。
- 再从剩余未排序元素中继续寻找最小(最大)元素,然后放到已排序序列的末尾。
- 重复第二步,直到所有元素均排序完毕。
# 时间复杂度
时间复杂度为,没有最好最坏的说法,效率不高。
# 实现
void SelectSort(int* arr, int n) | |
{ | |
for (int i = 0; i < n - 1; ++i) | |
{ | |
int min = i; | |
for (int j = i + 1; j < n; ++j) | |
{ | |
if (arr[j] < arr[min]) | |
{ | |
min = j; | |
} | |
} | |
if (min != i) | |
{ | |
Swap(&arr[i], &arr[min]); | |
} | |
} | |
} |
# 稳定性
直接选择排序是不稳定的。
# 2.2 堆排序
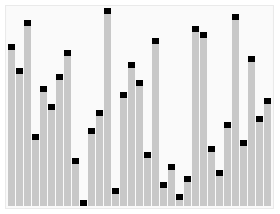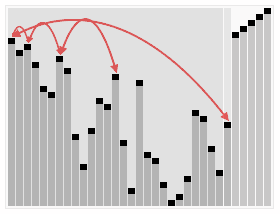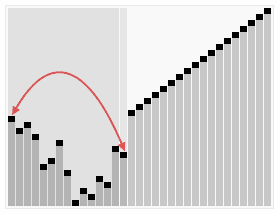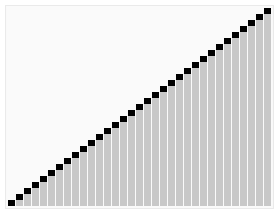
堆排序算法是利用大堆(或小堆)的性质来对数组进行排序的,相关内容在前几篇笔记已详细介绍。
堆排序的步骤:
- 建立堆: 将给定的无序数组构造成一个最大堆(为了升序排序)或最小堆(为了降序排序)。这个过程是通过将数组视为二叉树,然后从最后一个非叶子节点开始,向上调整每个节点,确保每个节点都遵循堆的性质,即每个父节点的值都大于其子节点的值(最大堆)或每个父节点的值都小于其子节点的值(最小堆)。
- 堆排序: 由于堆的根节点表示最大(或最小)元素,可以将其与堆的最后一个元素交换,然后将剩下的元素重新调整为最大(或最小)堆。重复这个过程,直到所有元素都被排序。
# 时间复杂度
堆排序的效率非常高,时间复杂度为。
# 实现
void AdjustDown(int* arr, int n, int parent) | |
{ | |
int child = parent * 2 + 1; | |
while (child < n) | |
{ | |
if (child + 1 < n && arr[child + 1] > arr[child]) | |
{ | |
++child; | |
} | |
if (arr[child] > arr[parent]) | |
{ | |
Swap(&arr[child], &arr[parent]); | |
parent = child; | |
child = parent * 2 + 1; | |
} | |
else | |
{ | |
break; | |
} | |
} | |
} | |
void HeapSort(int* arr, int n) | |
{ | |
for (int i = n / 2 - 1; i >= 0; --i) | |
{ | |
AdjustDown(arr, n, i); | |
} | |
int end = n - 1; | |
while (end > 0) | |
{ | |
Swap(&arr[0], &arr[end]); | |
AdjustDown(arr, end, 0); | |
--end; | |
} | |
} |
# 稳定性
堆排序是不稳定的。
# 三、交换排序
# 3.1 冒泡排序
冒泡排序是我们的老熟人了,是一种简单的排序算法,重复的遍历要排序的数列,一次比较两个元素,如果它们的顺序错误就把它们交换过来。越小(或越大)的元素会经过交换慢慢 “浮” 到数列的顶端,因此称为冒泡排序。
冒泡排序的步骤如下:
- 比较相邻的元素。如果第一个比第二个大(升序),就交换它们两个。
- 对每一对相邻元素做同样的工作,从开始第一对到结尾的最后一对。这步做完后,最后的元素会是最大的数。
- 针对所有的元素重复以上的步骤,除了最后一个。
- 持续每次对越来越少的元素重复上面的步骤,直到没有任何一对数字需要比较。
# 时间复杂度
时间复杂度为,而且大 O 表示法省略的常数不小,效率相当低。
# 实现
void BubbleSort(int* arr, int n) | |
{ | |
for (int i = 0; i < n - 1; ++i) | |
{ | |
int flag = 0; | |
for (int j = 0; j < n - i - 1; ++j) | |
{ | |
if (arr[j] > arr[j + 1]) | |
{ | |
Swap(&arr[j], &arr[j + 1]); | |
flag = 1; | |
} | |
} | |
if (flag == 0) | |
{ | |
break; | |
} | |
} | |
} |
# 稳定性
冒泡排序是稳定的。
# 3.2 快速排序
快速排序是一种非常高效的排序,基本思想是 ==“分而治之”==(将一个大问题分解成小问题)。
快速排序的核心是选择一个 “基准值”,然后将数组分为两部分:一部分包含小于基准值的元素,另一部分包含大于基准值的元素。通过递归不断对这两部分继续进行分区,直到整个序列有序。
快速排序的步骤如下:
- 选择基准值:从数列中挑出一个元素,称为 “基准”。
- 分区操作:重新排列数列,所有比基准值小的元素摆放在基准前面,所有比基准值大的元素摆在基准的后面(相同的数可以到任一边)。在这个分区退出之后,基准就处于数列的中间位置。
- 递归排序:递归将小于基准值的子数列和大于基准值的子数列重复前俩步来实现排序。
# 时间复杂度
快速排序的效率非常高,平均时间复杂度为,但最坏情况下会退化到。
但是非常神奇,这个最坏情况与其他排序不同,是在原数组有序或者接近有序的情况下为最坏情况。(越乱排序越快)
但是我们可以通过一些技巧来避免快速排序会取到最坏情况这件事,这会在下面介绍。
# 实现
# 原始的快速排序 - Hoare 法
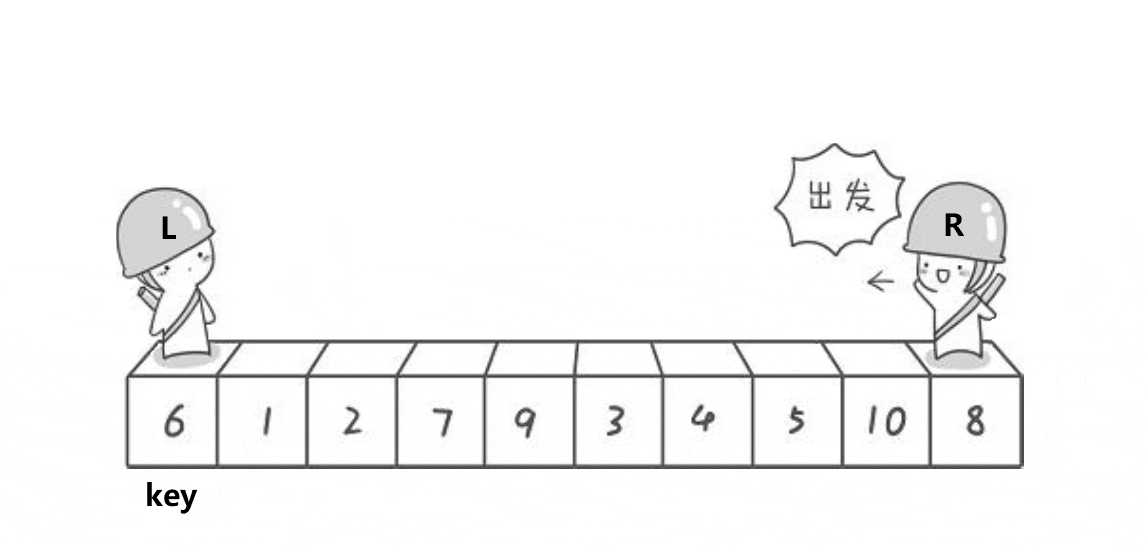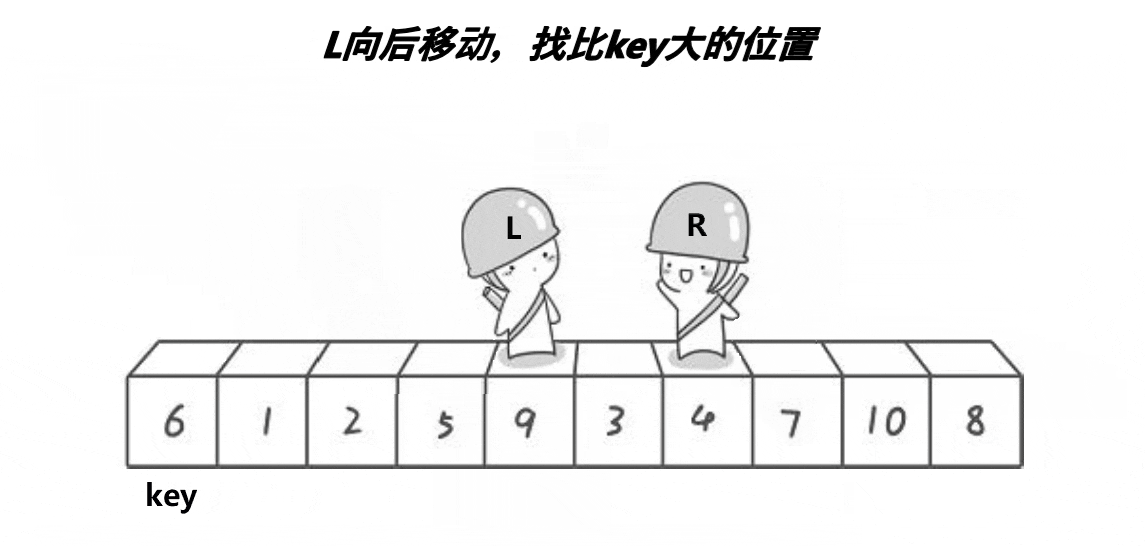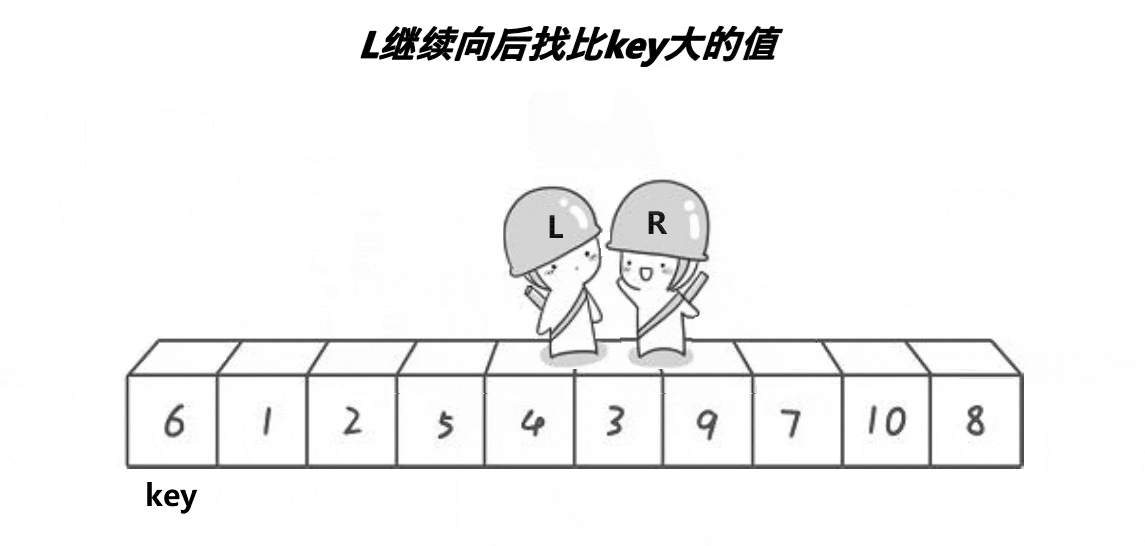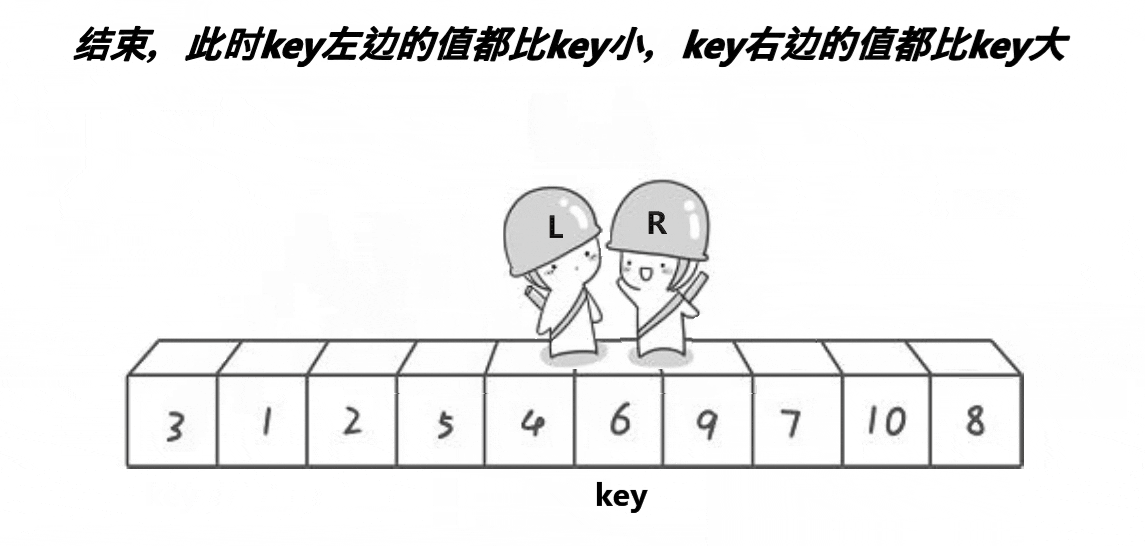
这是 Hoare 大佬刚提出快速排序时给出的方法。
我们记录排序区间的左下标 left 和右下标 right,并选取基准值 key 的下标(这边我们以 key=left 为例,若选择 key=right 下面反过来想就能得出)。我们使 right 从右往左跑直到找到小于基准值或者遇到 left,然后我们让 left 从左往右跑直到找到大于基准值或者遇到 right,随后交换 left 和 right 标记的值。重复这个过程就能完成一次分区,随后再写入递归即可完成排序。
void QuickSort(int* arr, int left, int right) | |
{ | |
if (left >= right) | |
{ | |
return; | |
} | |
int key = left, begin = left, end = right; | |
while (left < right) | |
{ | |
while (left < right && arr[right] >= arr[key]) | |
{ | |
--right; | |
} | |
while (left < right && arr[left] <= arr[key]) | |
{ | |
++left; | |
} | |
Swap(&arr[left], &arr[right]); | |
} | |
Swap(&arr[left], &arr[key]); | |
QuickSort(arr, begin, left - 1); | |
QuickSort(arr, left + 1, end); | |
} |
# 逻辑简洁的快速排序 - 挖坑法
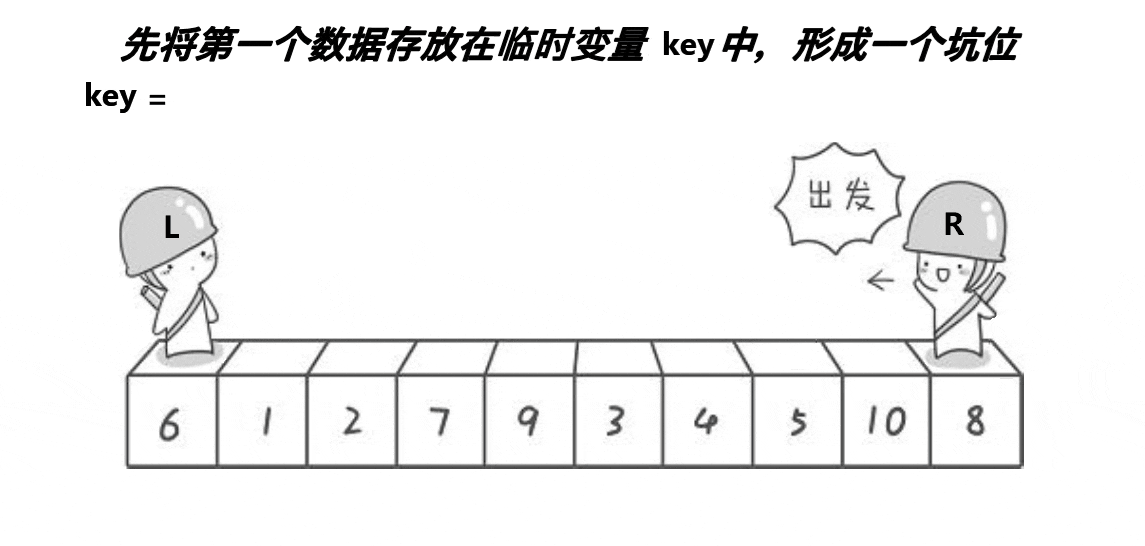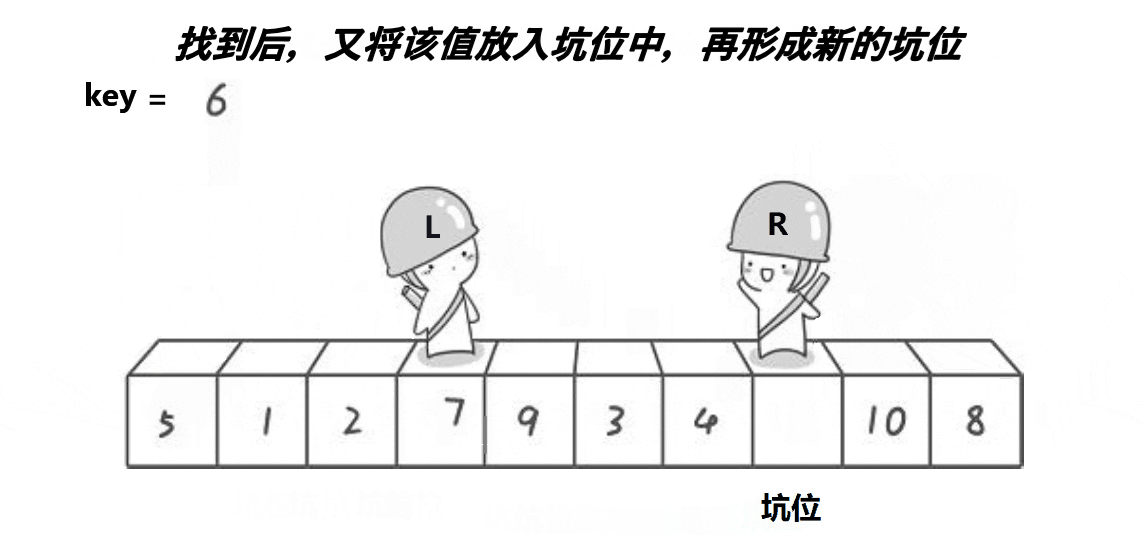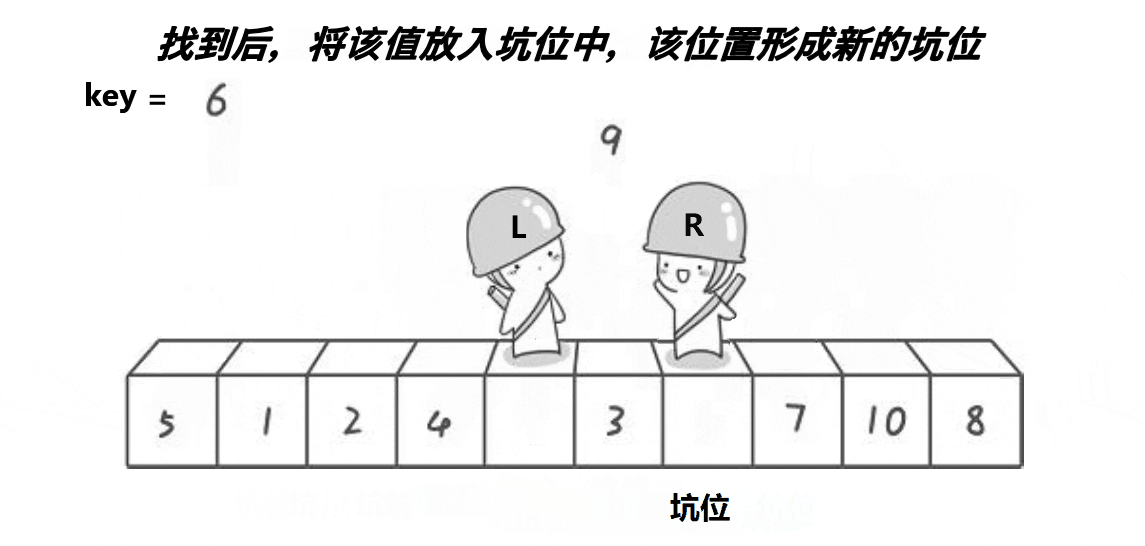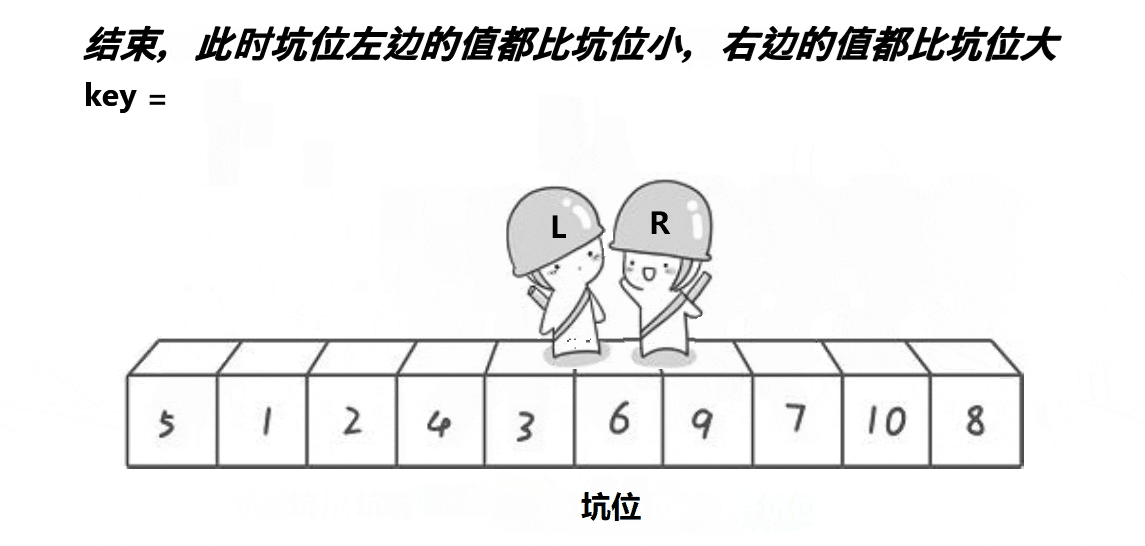
挖坑法在逻辑上更易于理解,不会陷入为什么左右标记不会越过对方、为什么一定要先移动某个标记等问题。
挖坑法就是把基准值单独复制出来放到一个变量里,原本的位置作为一个 “坑位”(还是假设 key=left)。然后右标记左移直到发现小于基准值的数,把这个数 “挖出来” 填到 “坑位” 里。这个时候挖走的形成了一个新的坑位,这时左标记右移直到找到大于基准值的数,再次挖到 “坑位” 里。重复这个过程直到两个指针相遇(数据都分区好了),最后把原本挖出去的基准值再填回来(这个时候坑位正好在中间)。这就成功完成了一次分区过程,递归即可。
void QuickSortDigHole(int* arr, int left, int right) | |
{ | |
if (left >= right) | |
{ | |
return; | |
} | |
int key = left, begin = left, end = right; | |
int tmp = arr[key]; // 挖坑 | |
while (left < right) | |
{ | |
while (left < right && arr[right] >= tmp) | |
{ | |
--right; | |
} | |
arr[left] = arr[right]; // 此时坑位从左边变为右边 | |
while (left < right && arr[left] <= tmp) | |
{ | |
++left; | |
} | |
arr[right] = arr[left]; // 此时坑位从右边变为左边 | |
} | |
arr[left] = tmp; | |
QuickSort(arr, begin, left - 1); | |
QuickSort(arr, left + 1, end); | |
} |
# 最好书写的快速排序 - 前后指针法
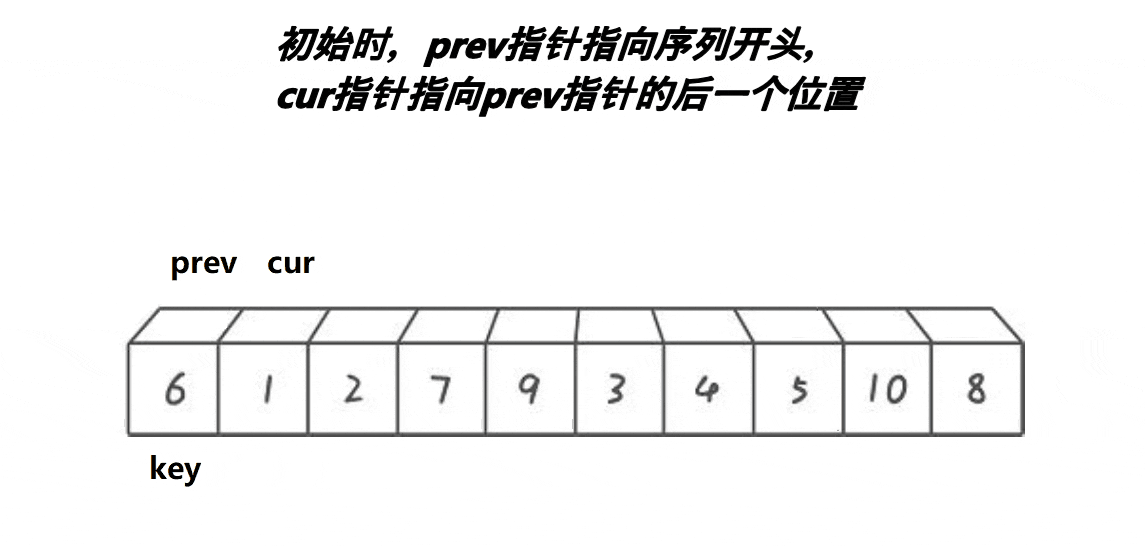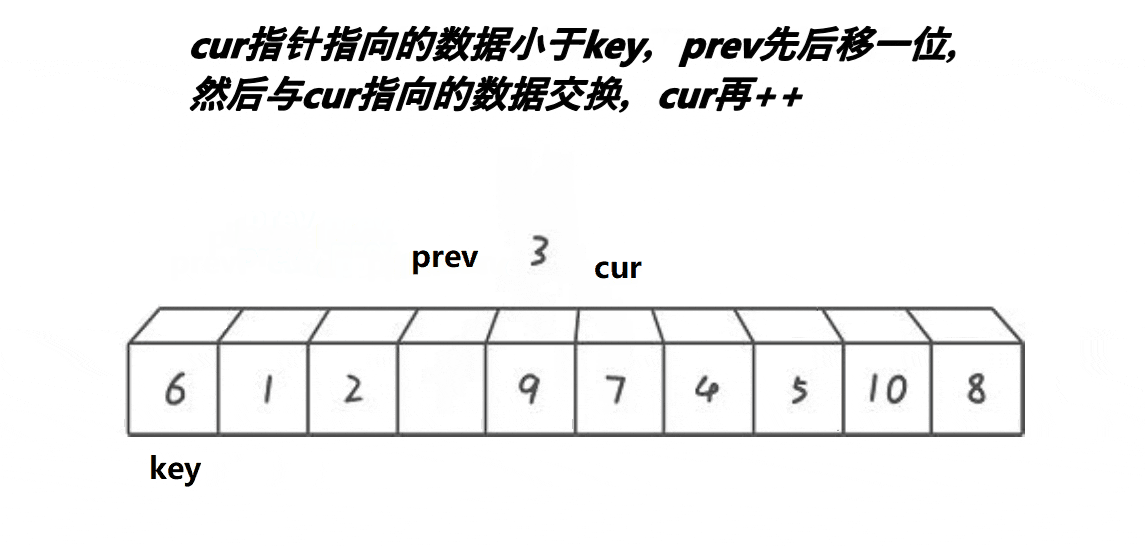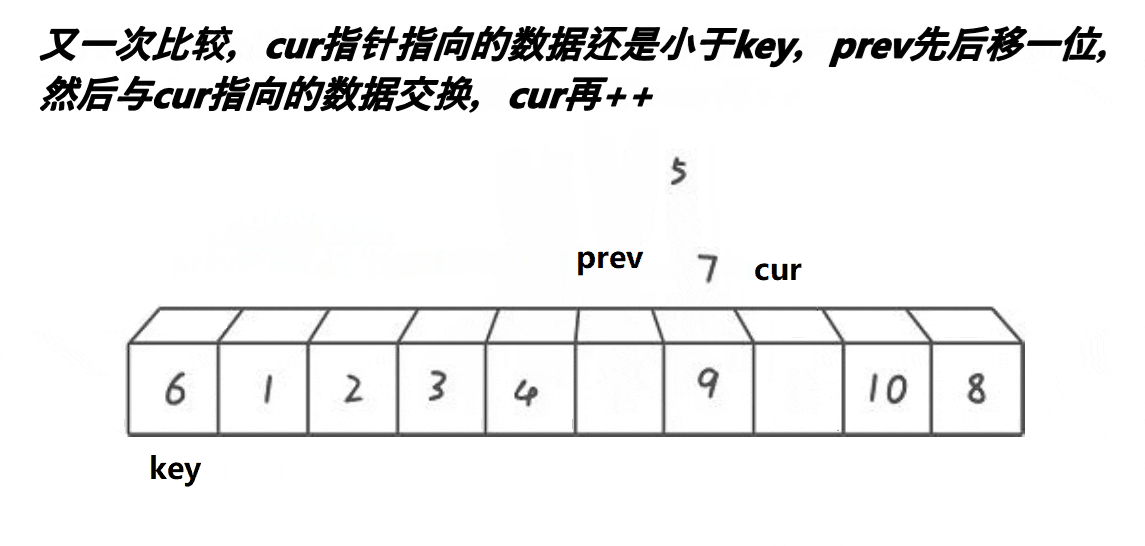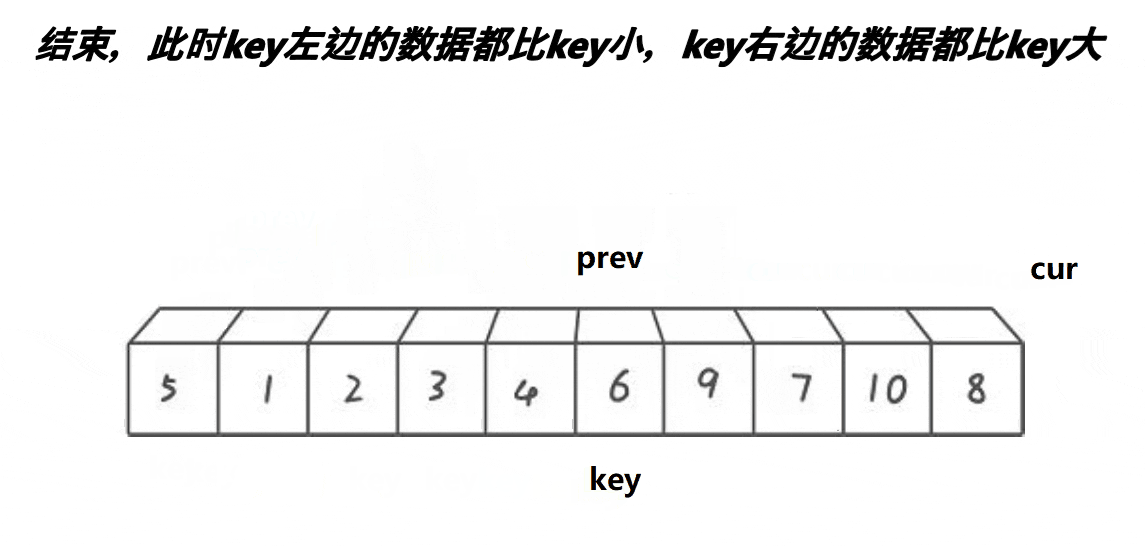
前后指针法的代码更简洁,也不难理解。
就是一开始把 prev 标记放在 left(还是假设 key=left),cur 标记放在 left+1,然后前指针 cur 一直往前冲,遇到比基准值小的数就和后指针 prev 标记的值对调,再让后指针往前一步。重复这个过程让小于基准的值全部堆到数组的前面(准确说是 prev 的前面),最后把 key 标记的值和 prev 标记的对调就完成了一次分区。 递归即可。
void QuickSortPrevCur(int* arr, int left, int right) | |
{ | |
if (left >= right) | |
{ | |
return; | |
} | |
int key = left, begin = left, end = right; | |
int prev = left, cur = left + 1; | |
while (cur <= right) | |
{ | |
if (arr[cur] < arr[key] && ++prev != cur) | |
{ | |
Swap(&arr[prev], &arr[cur]); | |
} | |
++cur; | |
} | |
Swap(&arr[prev], &arr[key]); | |
key = prev; | |
//[begin, key - 1] [key] [key + 1, end] | |
QuickSort(arr, begin, key - 1); | |
QuickSort(arr, key + 1, end); | |
} |
# 不使用递归的方法 - 栈模拟递归
这个方法没怎么好说的,就是用栈模拟递归,里面每一次分区依旧可以选择上面任意一种方法。
void InitStack(pStack pst) | |
{ | |
assert(pst); | |
pst->_data = NULL; | |
pst->_top = 0; | |
pst->_capacity = 0; | |
} | |
void StackPush(pStack pst, STDataType x) | |
{ | |
assert(pst); | |
StackCheck(pst); | |
memcpy(&(pst->_data[pst->_top]), &x, sizeof(STDataType)); | |
pst->_top++; | |
} | |
void StackPop(pStack pst) | |
{ | |
assert(pst); | |
assert(!StackEmpty(pst)); | |
pst->_top--; | |
} | |
STDataType StackTop(pStack pst) | |
{ | |
assert(pst); | |
return pst->_data[pst->_top - 1]; | |
} | |
void StackDestory(pStack pst) | |
{ | |
assert(pst); | |
free(pst->_data); | |
pst->_capacity = 0; | |
pst->_top = 0; | |
pst->_data = NULL; | |
} | |
void QuickSortNonR(int* arr, int left, int right) | |
{ | |
if (left >= right) | |
{ | |
return; | |
} | |
Stack st; | |
InitStack(&st); | |
StackPush(&st, left); | |
StackPush(&st, right); | |
while (!StackEmpty(&st)) | |
{ | |
int end = StackTop(&st); | |
StackPop(&st); | |
int begin = StackTop(&st); | |
StackPop(&st); | |
int key = begin; | |
int prev = begin, cur = begin + 1; | |
while (cur <= end) | |
{ | |
if (arr[cur] < arr[key] && ++prev != cur) | |
{ | |
Swap(&arr[prev], &arr[cur]); | |
} | |
++cur; | |
} | |
Swap(&arr[prev], &arr[key]); | |
key = prev; | |
//[begin, key - 1] [key] [key + 1, end] | |
if (begin < key - 1) | |
{ | |
StackPush(&st, begin); | |
StackPush(&st, key - 1); | |
} | |
if (key + 1 < end) | |
{ | |
StackPush(&st, key + 1); | |
StackPush(&st, end); | |
} | |
} | |
StackDestory(&st); | |
} |
# 区别
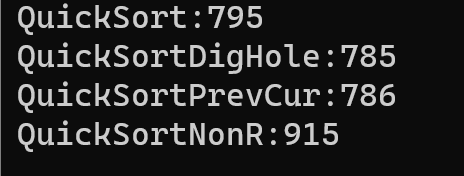
除了非递归的方法,这几个实现的时间复杂度并没有太多区别,使用非递归的方法会慢一点点。下面是对一千万个随机数据的排序测试(单位毫秒):
# 优化
# 随机选 Key 优化快速排序
这个方法是在序列中随机选一个值和首元素调换再作为基准值,大大减小了遇到最坏情况(每次选 key 是有序的)的可能。
void QuickSortRandomKey(int* arr, int left, int right) | |
{ | |
if (left >= right) | |
{ | |
return; | |
} | |
int key = left, begin = left, end = right; | |
// 生成随机数并将该位置与首位调换 | |
int random = rand() % (right - left + 1) + left; | |
Swap(&arr[random], &arr[left]); | |
while (left < right) | |
{ | |
while (left < right && arr[right] >= arr[key]) | |
{ | |
--right; | |
} | |
while (left < right && arr[left] <= arr[key]) | |
{ | |
++left; | |
} | |
Swap(&arr[left], &arr[right]); | |
} | |
Swap(&arr[left], &arr[key]); | |
QuickSort(arr, begin, left - 1); | |
QuickSort(arr, left + 1, end); | |
} |
# 三数取中优化快速排序
这个方法是取序列中 left、right、(left+right)/2 所对应的值的中位数与首元素调换作为基准值,这几乎完全避免了最坏情况的可能。
int GetMid(int* arr, int left, int right) | |
{ | |
int center = (left + right) / 2; | |
if (arr[left] > arr[center]) | |
{ | |
Swap(&arr[left], &arr[center]); | |
} | |
if (arr[left] > arr[right]) | |
{ | |
Swap(&arr[left], &arr[right]); | |
} | |
if (arr[left] > arr[center]) | |
{ | |
Swap(&arr[center], &arr[right]); | |
} | |
return arr[center]; | |
} | |
void QuickSortMidKey(int* arr, int left, int right) | |
{ | |
if (left >= right) | |
{ | |
return; | |
} | |
int key = left, begin = left, end = right; | |
// 三数取中 | |
int mid = GetMid(arr, left, right); | |
Swap(&arr[mid], &arr[left]); | |
while (left < right) | |
{ | |
while (left < right && arr[right] >= arr[key]) | |
{ | |
--right; | |
} | |
while (left < right && arr[left] <= arr[key]) | |
{ | |
++left; | |
} | |
Swap(&arr[left], &arr[right]); | |
} | |
Swap(&arr[left], &arr[key]); | |
QuickSort(arr, begin, left - 1); | |
QuickSort(arr, left + 1, end); | |
} |
# 小区间优化快速排序
当递归已经进行到序列变的很短的时候,依旧选择继续递归快速排序的效率其实较低,反而不如将已经较短的序列拿去进行插入排序。所以在递归时加上一个选择语句进行优化:
void QuickSortOptimized(int* arr, int left, int right) | |
{ | |
if (left >= right) | |
{ | |
return; | |
} | |
if (right - left < 10) | |
{ | |
InsertSort(arr + left, right - left + 1); | |
} | |
else | |
{ | |
int key = left, begin = left, end = right; | |
while (left < right) | |
{ | |
while (left < right && arr[right] >= arr[key]) | |
{ | |
--right; | |
} | |
while (left < right && arr[left] <= arr[key]) | |
{ | |
++left; | |
} | |
Swap(&arr[left], &arr[right]); | |
} | |
Swap(&arr[left], &arr[key]); | |
QuickSort(arr, begin, left - 1); | |
QuickSort(arr, left + 1, end); | |
} | |
} |
# 优化效果
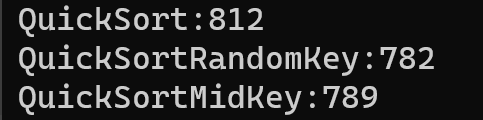
对于随机序列,随机选 key 和三数取中法并没有太大的作用:
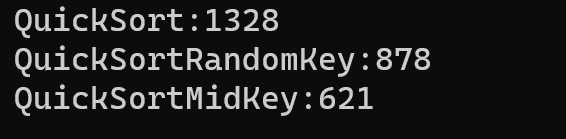
但是如果是有序或者近有序序列,就完爆原版了:
而小区间优化,说实话效果有限:

# 稳定性
快速排序是不稳定的。
未完待续。